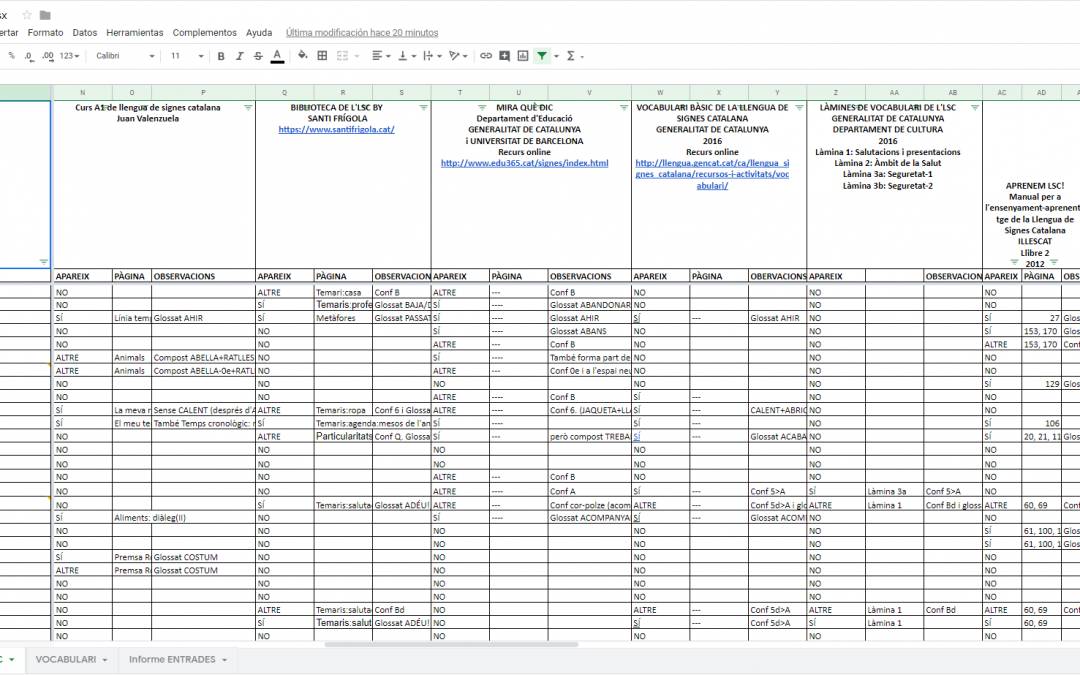
On February 9th, 2019, we already had enough material recorded and annotated to start with the second major project: the lexicographical database of LSC. The first task that we set ourselves within this second project was to extract all the signs of the general and specific dictionaries and other existing materials in LSC. We made a list of all the signs that appeared in the corpus, we linked each of these signs with a video (extracted from the same corpus), to obtain a visual representation of the sign. Once this was done, we begun to search in which LSC materials each of the listed signs appears. If we find it in a dictionary, we write down the reference where it comes from. If there is any variation regarding the image of the corpus sign that we watch, then we also write that down. This task has not yet been completed, but it is serving to verify that on many occasions the same sign receives different glosses and that on many other occasions the same gloss refers to different signs, which is normal when working with two different languages.
Press release 9 – LSC lexicographical database project