
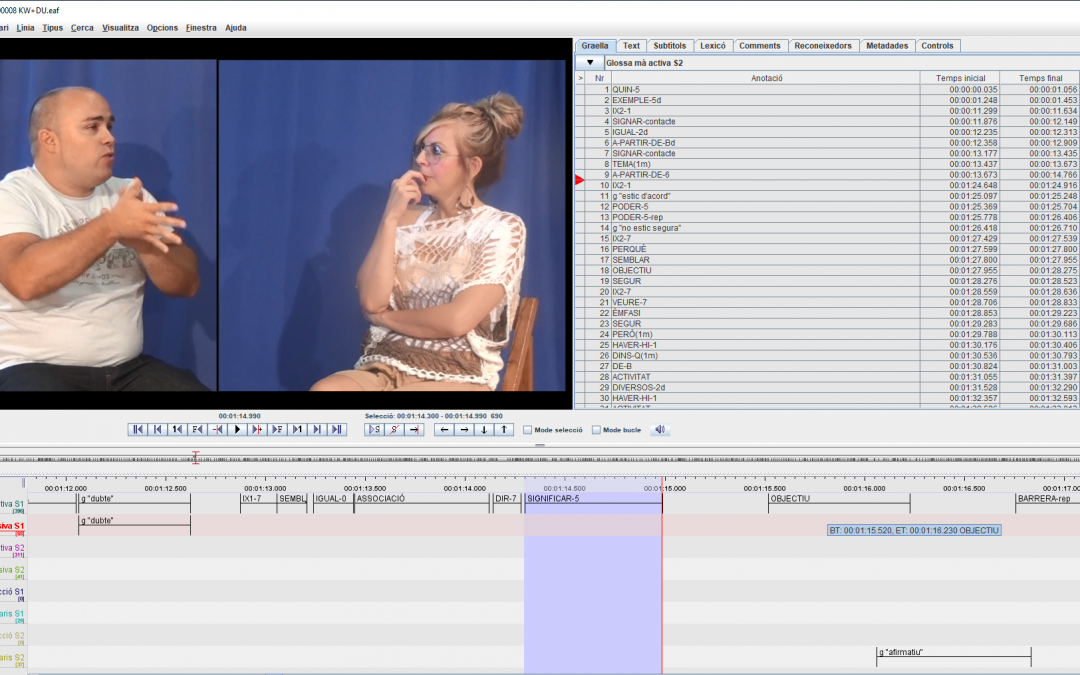
Currently there is no computer program that allows us to analyse the signs that appear in the recordings directly, that is, starting from the image. For this reason, after the recording it is necessary to synchronize the visual data with an annotation, in text format, that allows searching for any sign that appears in the recorded material. For our corpus, we decided to use the free ELAN program, created by the Max Planck Institute for Psycholinguistics in Nijmegen, the Netherlands (https://tla.mpi.nl/tools/tla-tools/elan/download/). This computer program allows segmenting each of the signs and annotating a word in text format that identifies it. Generally, this annotation in text format corresponds to one or more words of the closest oral language, which, in our project, is the Catalan language. However, the annotation work is not even remotely simple. The homogeneity and coherence in the annotations is very important in order to be able to make correct searches for signs. That is why we carry out many sessions of discussion and establishment of the annotation criteria, which we base on the previous work carried out in other Sign Language corpus projects, such as the NGT and the BSL(Sign Language of the Netherlands and British Sign Language, respectively). Here you have the links of these projects in case you are interested:
http://www.bslcorpusproject.org/