
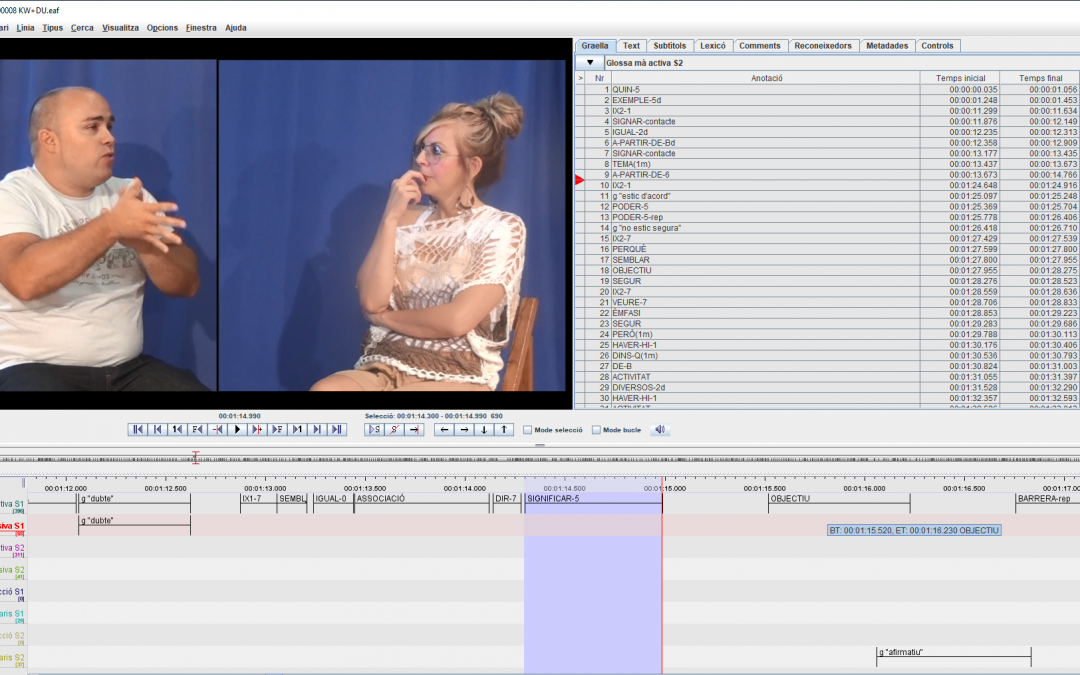
Actualmente no hay ningún programa informático que permita analizar los signos que aparecen en las grabaciones de forma directa, es decir, partiendo de la imagen. Por este motivo, después de la grabación es necesario sincronizar los datos visuales con una anotación, en formato texto, que permita buscar cualquier signo que aparezca en el material grabado. Para nuestro Corpus decidimos utilizar el programa gratuito ELAN, creado por el Max Planck Institute for Psycholinguistics de Nimega (Países Bajos) (https://tla.mpi.nl/tools/tla-tools/elan/download/). Este programa informático permite segmentar cada uno de los signos y anotar una palabra en formato texto que la identifica. Generalmente, esta anotación en formato texto se corresponde con una palabra o más de la lengua oral más próxima, que, en nuestro proyecto, es la lengua catalana. No obstante, el trabajo de anotación no es para nada sencilla. La homogeneidad y la coherencia en las anotaciones es muy importante para poder hacer búsquedas correctas de signos. Por eso llevamos a cabo muchas sesiones de discusión y de establecimiento de los criterios de anotación, que basamos en los trabajos previos realizados en otros proyectos de corpus en lenguas de signos, como el de la NGT y la BSL (lenguas de signos de los Países Bajos, y británica, respectivamente). Aquí tenéis los enlaces de esos proyectos por si pueden ser de vuestro interés:
http://www.bslcorpusproject.org/